#討論 自製 A/B testing 統計引擎的二三事
========== 我是分隔線 下面自我 Q&A ==========
Q1: 為啥這次是用 #討論 而不是 #分享
A1: 因為這次查了很多資料但是還是沒搞懂,所以我是上來找大神的
Q2: ......
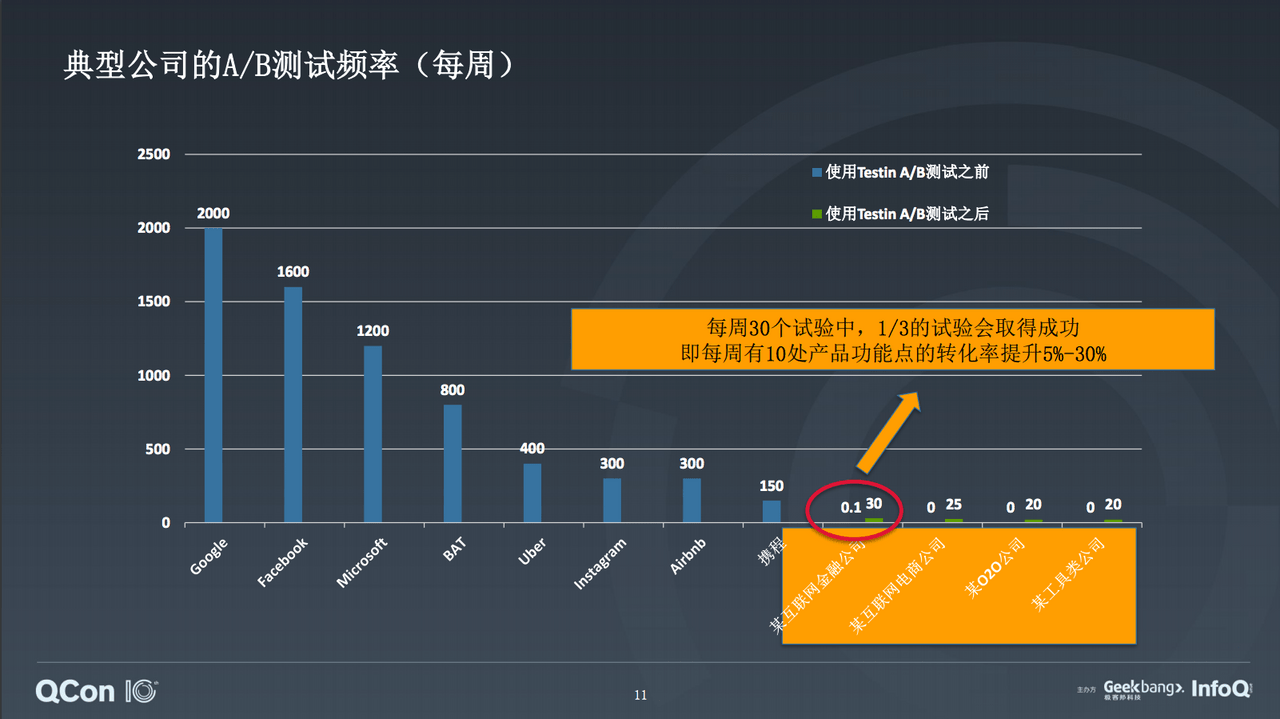
前情提要一下:上次去北京學到的兩點:
1⃣️、A/B testing 的頻率與公司規模成正比: