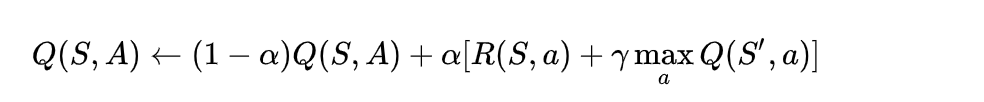#分享 吃角子老虎(Bandit) 問題 - Multiarm Bandit
最近依然在跟推薦系統奮鬥,中間我們做出了好幾種 poc,在 AB testing 的過程當中,怎樣分配流量才能夠不太損失公司的利益,又能同時檢驗出哪個 poc 效果最好呢?其中一種做法就是 Multi-armed banditMulti-armed bandit原本是從賭場中的多臂老虎機的場景中提取出來的數學模型,其中 arm 指的是老虎機(slot machine)的拉桿,bandit 是多個拉桿的集合*Tt8A6mP98ibBlrlFD5UJxg.png
大家可以想像賭場有四台吃角子老虎機,每一台賺錢的機率如上圖所示,那怎樣才能轉隊多錢呢?想必是一直去玩左邊那台老虎機對吧?但是這些機率其實是你量出來的,我們並不知道他真正的機率,只能自己去多玩幾次來求得一個逼近真實的機率。那你可能會想問,這張圖顯示的機率真的準嗎?好問題,不知道🤔,這個機率有可能是有 bias 的,所以得要多方嘗試其他的老虎機來極大化收益。
以 epsilon=10%-greedy 為例子,就是 90% 的時間都去玩左邊的老虎機,10% 的時間去探索新的老虎機看看他們的收益有沒有比較高,90% 的行為被稱作 exploit (greedy 的行為),10 % 的行為被稱作 explore (因為是去探索有沒有更高收益的機器)。比例是可以調整的,可以完全的 exploit or explore
每一輪探索玩老虎機之後,我們怎麼更新老虎機的機率呢(也就是收益,reward)?
這邊有各種實作,目前我看到最屌的是結合 Q-Learning 的 action-value function 來更新 reward(請看下圖)。查了一下才發現,Multi-armed bandits 是 reinforcement learning 的一員,論資歷還比 Q-Learning 資深呢XD