#分享 Triton武林秘籍:初探CPU運作原理

在軟體開發的江湖中,最近出現了一門新興的武林秘籍——Triton。傳聞這門武學能讓習武之人(開發者)以簡易的 Python 招式寫出媲美底層CUDA功力的絕世武功(高效Kernel) 。本文將以金庸武俠小說的風格,帶領初學者走進Triton門派的世界,探究其武學心法與運作奧秘。其中包括:@triton.jit絕學的用途、Triton編譯的多層內功心法(從Python原始招式轉化為MLIR再降階為LLVM IR),以及Triton與LLVM這位武林盟主的關係(如何借助LLVM強化功力,以及目前對CPU平臺修行的支援狀況)。故事情節雖為比喻,但技術對應皆有理可循,盼讀者在嬉笑間領悟箇中真意。
引子:少年闖蕩「Triton」門派
話說在軟體武林中,一位初出茅廬的少年開發者,機緣巧合下得到了一本名為《Triton心法》的秘籍殘卷。傳聞修習此心法者,可在GPU武道上迅速提升功力,寫出的招式速度堪比手撰CUDA匠藝而不失靈活 。少年不遠萬里尋訪,終於來到Triton門派的山門。只見門口匾額高懸,刻著「Triton」二字,氣勢不凡。守門弟子告知:「本門以Python語言傳功,不需深入CPU/GPU底層,便可寫出絕妙武功」。少年大喜過望,決心拜入門下,一探這門派的奧妙。
@triton.jit:閉關修煉的「即時」絕學
拜師入門後,少年首先接觸到的是Triton門派的入門絕學——@triton.jit。掌門人告訴他:「此乃本門獨門秘技,能將你的Python招式在關鍵時刻即時淬鍊成威力強大的內功Kernel。」原來,平時弟子只需以Python撰寫普通的函數招式,再在函數上貼上@triton.jit這道符印,待日後真正施展(調用)時,秘籍中的奧義將瞬間運轉,將這招式編譯成高速運轉的內核級攻擊,直接在GPU上執行 。
舉個例子,少年學會了一招「向量相加術」,用Python寫成函數並以@triton.jit裝飾。當他首次使出此招時,Triton編譯器立即啟動,在背後將這招式轉化為GPU能理解的機械語言Kernel,併發於數千線程之間 。日後再使此招,因已編譯練成,便可毫無遲滯地發出,迅捷無比。正如武林中高手閉關修煉內功心法,一朝大成後再出關,出招迅猛且內力深厚。對應到技術實現上,@triton.jit 的作用就是即時編譯 (JIT):在函數第一次執行時,將其編譯為高效的GPU內核,以後重複調用時直接使用已編譯的版本,極大提升了執行效率 。
值得一提的是,Triton門下習武採用的是單一程序多數據(SPMD)模型。每當弟子施展帶有@triton.jit的招式,彷彿同一套武功由眾多弟子同步施展——每個Kernel好比一個門下弟子,同時執行相同的招式但作用於不同的數據對象 。Triton心法會自動將這些弟子的動作對齊映射到GPU硬體的執行單元(如執行緒、warp),確保招招協調一致,威力覆蓋整個戰場 。如此一來,初學者無需深諳CUDA底層的繁文縟節,只消專注招式本身,透過Triton的JIT秘技,即可達到高並行、高效能的武學境界。
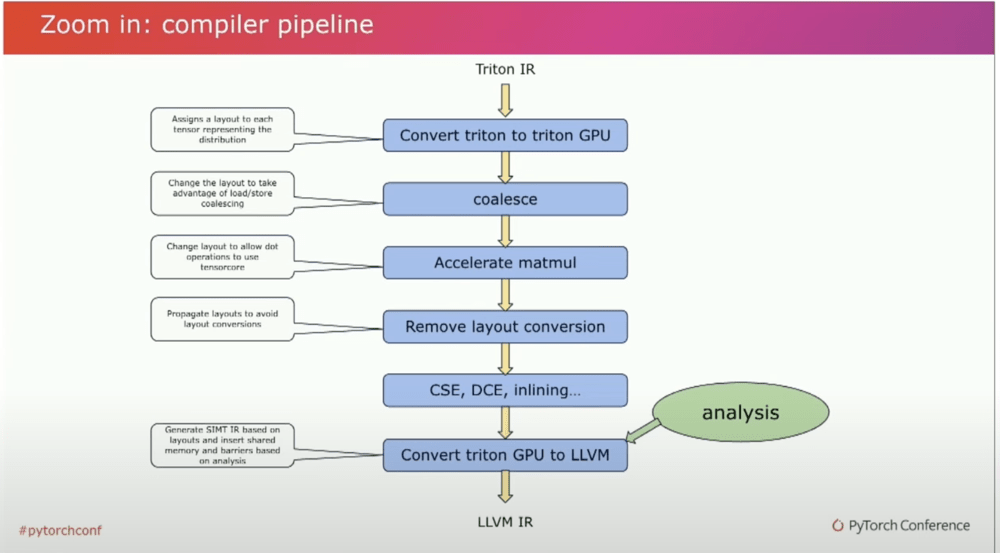
多層內功心法:從Python招式到MLIR再到LLVM
少年苦練數月,終於掌握了幾招基本功。但他不禁好奇:Triton的武學內功是如何運轉的? 為何一段Python招式貼上符印後,就能化為強大的GPU內核?師父笑道:「這就牽涉到本門深奧的多層內功心法了!」接著便向少年講解Triton編譯過程的層層奧義。