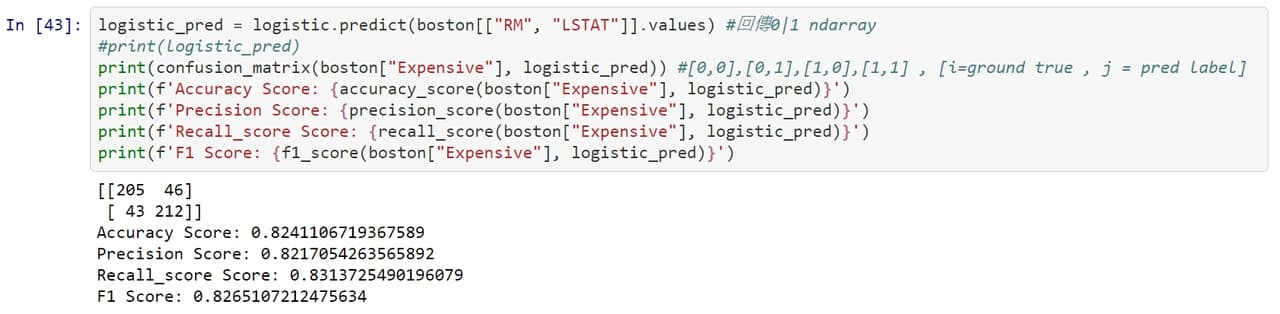
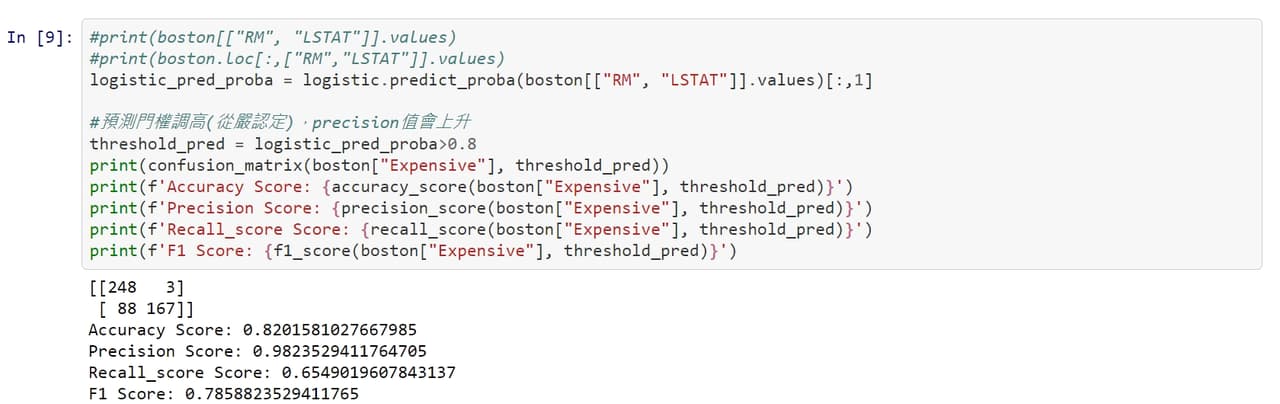
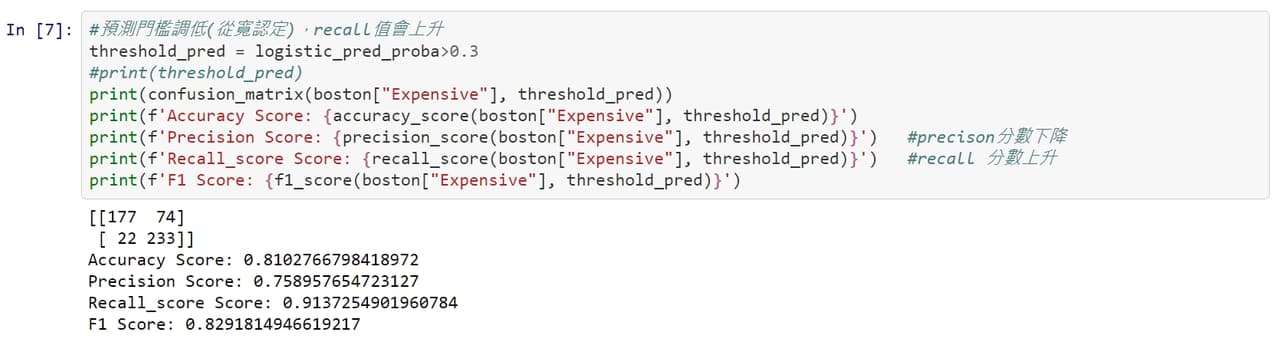
#分享 聊聊機器學習模型的評估方法 - 混淆矩陣(Confusion Matrix)
國立臺灣大學
◆如何評估機器學習模型的好壞?
當我們辛辛苦苦訓練好一個機器學習模型時,我們要怎麼評估訓練的模型到底好不好?也就是訓練的成效(Performance) 。 要量化這些成效我們必須先了解到有哪些靠譜驗證指標可以用來進行評估(Performance indexes) 。
依照問題種類一般會有「分類指標」和「回歸指標」,顧名思義,分類指標是用來評估分類問題的成效,回歸指標是用來評估回歸問題的成效。而我們討論的混淆矩陣就是一種分類指標,本篇先從二元分類的混淆矩陣開始介紹起。
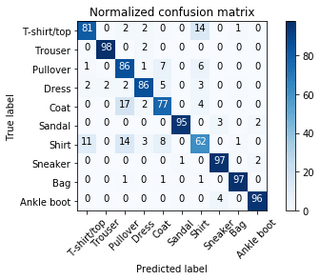
◆關於混淆矩陣
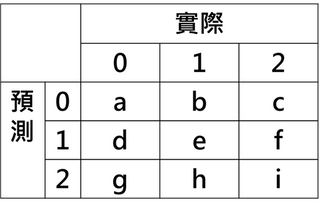
混淆矩陣是除了ROC曲線和AUC之外的另一個判斷好壞程度的方法,通常用於二元分類。二元分類基本上就是「真」| 「假」或是YES | NO , 而這兩種狀況又分成「真實結果」的YES | NO 以及 「預測結果」的 YES | NO, 我們將這些情況使用一個二維矩陣來圖解: